
By Johannes C. Scholtes, Chief Data Scientist, IPRO
Introduction
“One morning I shot an elephant in my pajamas. How he got in my pajamas, I don’t know.”
A classic example of the Marx Brothers’ humor, which often relied on rapid-fire jokes and absurd scenarios. Why is human language, let alone humor, so hard to understand for computer programs?
Human language is difficult for computer programs to understand because it is inherently complex, ambiguous, and context-dependent. Unlike computer languages, which are based on strict rules and syntax, human language is nuanced and can vary greatly based on the speaker, the situation, and the cultural context.
What are the key challenges in understanding human language?
- Ambiguity: Words and phrases can have multiple meanings depending on the context in which they are used. For example, the word “bank” can refer to a financial institution or the side of a river.
- Idiomatic expressions: Many expressions and phrases in human language are idiomatic and cannot be translated literally. For example, “kick the bucket” means to die, but the words themselves have no connection to death.
- Context dependence: The meaning of a word or phrase can change depending on the surrounding words and the larger context in which it is used. Often, such relations are long distance relations, referring to words elsewhere in the sentence or in other sentences (at least, if the text is well written).
- Spelling and grammatical variations: Human language is full of variations in spelling, grammar, and usage, making it difficult to create a set of strict rules for understanding and interpreting it.
- Dealing with lexical, syntactical, or semantical errors, slang, or just bad writing skills.
As a result, building computer programs that can accurately understand and interpret human language has been an ongoing challenge for artificial intelligence researchers.
Generative grammar and linguistic ambiguity
During English lectures, we’ve learned that language consists of grammatical structures, syntax and various word and phrase relations. In computational linguistics and natural language processing, these were exactly the tools used by the early computer programs.
Generative grammar, as initially proposed by Noam Chomsky, is designed to generate possible grammatical structures of sentences in a language. It describes a set of rules and principles that are used by a speaker of a language to generate an infinite number of sentences. While this grammar has been successful in explaining the underlying structure of sentences and language acquisition, it cannot fully resolve linguistic ambiguity.
Let’s take a look at the Marx Brothers’ joke. Linguistic ambiguity arises when a sentence or phrase has more than one possible meaning, often due to multiple interpretations of a word or phrase. Is the “elephant supposedly wearing the speaker’s pajamas, rather than the speaker shooting the elephant while wearing their own pajamas.”
Visually, the syntactic parses would look like the following:
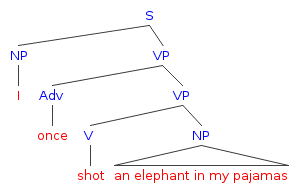
Reads as: ‘I once shot an elephant, who was wearing my pajamas’.
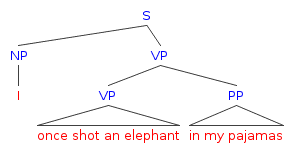
Reads as: ‘Wearing my pajamas, I once shot an elephant.’
A full-depth syntactic parser would probably also come up with another solution: ‘there is an elephant hiding in my pajamas, that I shot’.
Generative grammars cannot resolve linguistic ambiguity because they do not consider the pragmatic context in which a sentence is used. Generative grammars focus on the syntactic structure of a sentence, but they do not account for contextual information that can disambiguate the meaning of a sentence.
Linguistic ambiguity is great source of humor, but it can also cause real-life problems. A classic example is the legal case Liparota v. United States, a supreme court decision of 1985. See the appendix for more detail on this to understand that even (well-educated) human beings have challenges dealing with linguistic ambiguity.
This is exactly the reason why it took us so long to create reliable computer programs to deal with human language.
Deep learning and natural language processing models
Already in the 1990s, linguistics started adding linguistic probability to syntactic structures, allowing the models to choose the most ‘logical’ meaning. However, such models could not really deal with more complex linguistic phenomena such as word-order differences in translation (alignment), semantics, homonyms, synonyms, subject-predicate-object relations, co-references, pronoun resolution, speech-acts, pragmatics, etc. There were even initial experiments with deep learning and natural language processing. But, we lacked computational power, training data and the right algorithms.
Over the years, step-by-step, new models addressed these problems:
- Statistical feature functions allowed for the understanding of more complex and long-distance linguistic relations.
- Word-embeddings such as word-2-vec were better at synonyms.
- Bi-directional word-embeddings such as Elmo and BERT were better for homonyms.
- Encoding-decoding mechanisms dramatically increased the quality Q&A (ChatBots) and translation allowing the use of machine learning.
- Attention addressed alignment problems in translation.
But all of these models still took shortcuts and none of them addressed all linguistic challenges. It was not until Google introduced the Transformer model in 2017 in the ground-breaking paper “Attention is all you need”. Here, a full encoder-decoder model, using multiple layers of self-attention resulted in a model capable of understanding almost all of the linguistic challenges. The model soon outperformed all other models on various linguistic tasks such as translation, Q&A, classification, text-analytics.
BERT & GPT
From the original Transformer model, a variety (also called a zoo of transformer models) has been created. The two best known models are: BERT and GPT.
BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) are both state-of-the-art deep learning models used for natural language processing (NLP). However, they differ in their architecture and use cases.
- BERT is a pre-trained transformer-based neural network model designed for solving various NLP tasks such as question answering, sentiment analysis, and language translation. It is bidirectional, meaning that it can take into account both the left and right context of a word in a sentence when making predictions. BERT is pre-trained on large amounts of text data and fine-tuned on specific tasks, making it highly effective in transfer learning. BERT is commonly used for tasks that require understanding of the meaning of words in a sentence, such as sentiment analysis or question answering.
- GPT, on the other hand, is a language model that is specifically designed for text generation tasks. It uses a unidirectional transformer architecture, meaning that it only looks at the left context of a word in a sentence when generating text. GPT is trained on large amounts of text data and can generate coherent, human-like text in response to a prompt. GPT is commonly used for tasks such as text completion, text summarization, and text generation.
In summary, while both BERT and GPT are transformer-based neural network models used for NLP, they differ in their architecture and primary use cases. BERT is bidirectional and is typically used for NLP tasks that require understanding the meaning of words in a sentence, while GPT is unidirectional and is specifically designed for text generation tasks.
ChatGPT is an extension of GPT. It is based on the latest version of GPT (3.5) and has been fine-tuned for human-computer dialog using reinforcement learning. In addition, it is capable to stick to human ethical values by using several additional mechanisms.
The core reason of ChatGPT is so good because transformers are the first computational models that take almost all linguistic phenomena seriously. Based on Google’s transformers, OpenAI (with the help of Microsoft) have shaken up the world by introducing a model that can generate language that can no longer be distinguished from human language.
ChatGPT is not perfect yet, there is still room for improvement. The AI research community will undoubtably introduce new and improved models: larger models, optimized for certain vertical applications such as legal & medical, co-pilots for specific tasks such as searching, programming, document drafting, eDiscovery and information governance.
Currently, we are witnessing the largest AI experiment ever, and we are all part of it!
2023 will be the year we experience a watershed moment for natural language processing and artificial intelligence. Enjoy the moment!
Appendix
Linguistic ambiguity is great source of humor, but it can also cause real-live problems. A classic example is the legal case Liparota v. United States, a supreme court decision of 1985. See the appendix for more detail on this.
The statute there imposed criminal penalties on anyone who “knowingly uses, transfers, acquires, alters, or possesses [food stamps] in any manner not authorized by [law].” The question was whether someone who used, transferred, acquired, altered, or possessed food stamps illegally could be convicted without proof that they knew that their use, transfer, etc. was illegal.
The statute could be read in two ways, each of them associated with a different phrase structure. [Update: See the note at the end of the post.] The government argued for an interpretation in which knowingly modified only the phrase ‘uses…food stamps’:
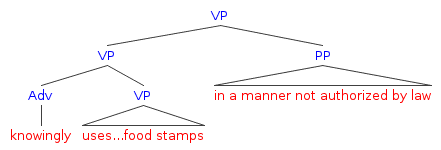
The defendant, on the other hand, argued that knowingly modified the larger phrase ‘uses…food stamps’ in any manner not authorized by law:
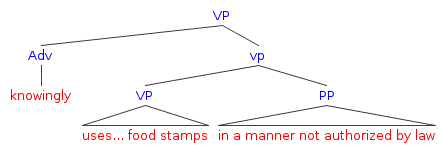
So, even human beings have trouble with linguistic ambiguities.


